Data preparation is the procedure of gathering, combining, structuring, and organizing data so it can be used in business intelligence (BI), analytics, and data visualization applications. It is the process of extracting raw data and getting it prepared for ingestion in an analytics platform. The data preparation procedure is done by information technology (IT), BI, and data management teams as they combine data sets to save into a data warehouse then further analytics applications are created with those data sets. In the world of data, there is a rule that everyone knows: 80% of a data scientist’s time is spent preparing his data, and only 20% working on it, especially its visualization.
The primary purposes of data preparation are to ensure that raw data being readied for processing and analysis is accurate and consistent. Data is created with missing values, inaccuracies, or other errors, and different data sets usually have other structures that need to be reconciled when they are united. Data preparation influences discovering accurate data to ensure that analytics applications produce significant data and actionable insights for business decision-making.
Meanwhile, in an article on preparing data for machine learning, Felix Wick, corporate vice president of data science at supply chain software vendor Blue Yonder, is quoted as saying that data preparation "is at the heart of ML."
Know Why is data preparation being important for ML
Data fuels ML. Harnessing this data to reinvent your business, while challenging, is crucial to staying appropriate now and in the future. It is the survival of the most informed, and those who can put their data to work to make better, more informed decisions respond faster to the unexpected and uncover new opportunities. This critical yet tedious method is a prerequisite for creating exact ML models and analytics, and it is the highest time-consuming element of an ML project.
To lessen this and gain the output of data preparation, data scientists can operate tools that help automate data preparation in various forms. So, let’s know its processes.
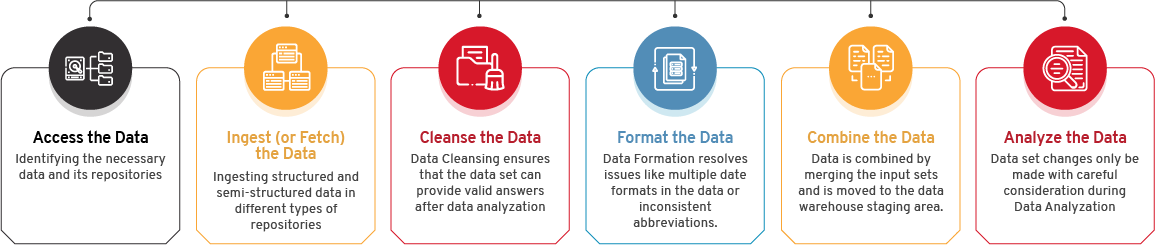
Process Insights of Data Preparation:
Exploring:
Before data can be prepared, analysts should know about the data. The analysts can see the content of the data and let them assess column-level distributions, anomalies in the data, patterns in the data structures, and many more areas. Now, they can better determine how the data will be prepared.
Structuring:
Raw data comes in different designs and sometimes with no structure. It is the key to providing the raw data structure by adding columns or rows in unformed data sets, dragging vital information, flattening arrays into rows, or splitting raw data into columns.
Cleaning:
The identified data errors and issues are corrected to create complete and accurate data sets. Here, faulty data is removed or fixed, missing values are filled in and inconsistent entries are harmonized.
Enriching: Enriching data help in creating a complete picture of the data set. Analysts will join fields and decide which fields are the finest for unions or joins.
Shaping:
The optimization of raw data can consist of data pivoting, filtering, aggregating data, creating new fields, or encoding columns.
Challenges:
Before the automation, there were some challenges in the Data Preparation process. Have a look at them below.
Historically, data preparation has been very time-consuming. It is popularized that up to 80% of the total analysis process is spent on cleaning or preparing data. However, in current years data preparation has grown in size and become more challenging and is usually relegated to the technical employees of a company.
But when data preparation lives behind technological hindrances, this introduces new challenges:
The organization’s costliest resources are tied down with preparing data and are unable to solve more challenging data problems.
The business analysts, or those who know the data best, are unable to get involved with the preparation process themselves. They lack visibility into their raw data, which has the potential to transform their requirements and, ultimately, their analysis.
Benefits:
Data scientists usually complain that they devour most of their time gathering, cleansing, and structuring data rather than analyzing it. The best advantage of a useful data preparation process is that the end users can concentrate more on data mining and data analysis, the elements of their job that develop business value.
Data preparation helps an organization to do the following:
- Assure the data used in analytics applications delivers trustworthy outcomes;
- Recognize and resolve data issues that otherwise might not be noticed;
- Facilitate more instructed decision-making by business managers and active workers;
- Reduce data management and analytics costs;
- Avoid repetition of action in preparing data for benefit in numerous applications;
- Get more increased ROI from BI and analytics endeavors.
Use Cases on Data Preparation by CSM
Mining:
CSM has developed a DLMS (Digital Logistics Management System) dashboard in JSW mines with the help of Data Preparation in ML. As the Permit data is discovered, the collected data is then cleansed, organized, and transformed for validation in the permit management system (i3MS or similar system for permit management) and Permit assignment to transporter tagged with trip and route details (optional in case of non-miners).
Social Registry:
CSM implemented SPDP (Social Protection Delivery Platform) in Odisha, Janadhar in Rajasthan, and SRIS (Social Registry Information System) in the Gambia with the help of Data preparation where the master data of the public is collected from various databases sanitized and organized for validation. Then, the Golden records are formed with the help of ETL.
Agrigate:
In the Agrigate domain offering, CSM implemented ML supported data preparation in paddy analytics for the Crop One solution, where three data sets (Farmer registration data, Land details & Satellite Data) are prepared to create a genuine record of farmers. After the process of data preparation, the prepared data is then integrated with the farmer details, and the token is generated for paddy procurement through PPAS (Paddy Procurement Automation System).
State Dashboard:
In J&K UT Dashboard and Odisha State Dashboard, CSM has expertise in data preparation where the collected data is discovered, cleansed, organized, and transformed for validation and ETL process is used in the integration of the prepared data in displaying analytics for the dashboard as per KPI (Key Performance Indicator).
Covid Dashboard used data preparation process was used for providing vital information relating to the spread of the pandemic for effective decision making. The data preparation of the collected data of affected, recovered, and the death rate is analyzed, and then transformed for validation. And then this prepared data is integrated by ETL and loaded for the dashboard. In such unpredictable times, this solution truly enables evidence-based policymaking by administrators to remain one step ahead in the fight against the pandemic.